Imagine clicking a link to a 500-page report and watching the first page appear in milliseconds and not minutes. That is exactly what PDF linearization delivers. Whether you call it a linearized PDF, fast web view, or simply a linearized PDF, the concept is the same: a smarter way to structure your PDF file so that remote users can start reading almost immediately, rather than waiting for the entire document to transfer.
In this guide, we break down the linearized PDF meaning, explain how PDF linearize works under the hood, walk through when to use it, and show you how to create linearized PDF files.
What Is PDF Linearization? (Linearized PDF Meaning)
PDF linearization, or linearisation in British English, is a method of restructuring the internal layout of a PDF file so that its pages can be delivered incrementally over a network, rather than requiring a complete download before display.
If you have ever asked what is linearized PDF, here is the simplest answer: it is a version of a PDF file that is reorganized internally so viewers can display the first page almost instantly, even before the rest of the file finishes downloading.
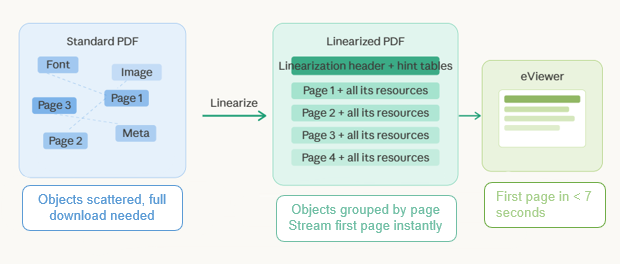
Think of a standard PDF as a warehouse where boxes (pages and their resources) are stored in random order. To find any one box, you would need to search the entire warehouse. A linearized PDF, by contrast, is like a warehouse with perfectly labeled, sequentially arranged shelves so you can walk straight to what you need.
The PDF specification introduced linearization in version 1.2, dedicating more than 20 pages to it in the core reference. It is also commonly called “Fast Web View” because it fundamentally accelerates how quickly web-served documents become usable.
PDF Linearization: Stream documents instantly over any network
PDF Linearization: Stream documents instantly over any network
How Linearizing Works – Fast On-Demand Page Streaming
To understand the linearized PDF meaning at a technical level, it helps to know how PDFs are organized internally.
The Object Tree Problem in Standard PDFs
Every PDF has a number of objects, including pages, fonts, images, metadata, and more, all connected by reference numbers. In a non-linearized PDF, these objects are stored wherever the authoring software chose to place them, often scattered throughout the file. When a viewer needs to render page one, they may discover that the required font lives at the very end of a 200 MB file. The result: the entire file must download before anything can display.
How the Linearized Structure Solves This?
The PDF linearize process reorganizes the object tree so that each page’s resources (fonts, images, form fields, etc) are grouped together in document-page order. Two key additions enable random online access:
- Linearization Dictionary: Placed right at the start of the file, this header advertises the document’s linear structure and provides critical byte offsets.
- Hint Tables: Stored near the top as well, these act as a precise map indicating exactly where in the byte stream each page’s resources are located.
A linearization-aware viewer (such as MS Technology’s eViewer) can read the hint tables first, then issue precise byte-range HTTP requests to fetch only the data needed for the current page.
Smart Page Prioritization in Practice
Here is what happens when a user opens a 2,000-page linearized PDF using eViewer:
- The viewer fetches the linearization header and hint tables — a tiny fraction of the file.
- It immediately fetches and renders a few initial pages for the user.
- Background downloads fill in the rest of the document progressively.
- If the user jumps to a specific page, eViewer prioritizes rendering of the requested page first while other pages are being rendered in the background.
Our own testing — and feedback from enterprise clients — confirms that linearized PDFs can render the first page of a 50 MB document in under 7 seconds over a standard 4G connection.
PDF/A vs Linearized PDF — What Is the Difference?
A common question among document professionals is: what sets PDF/A vs linearized PDF apart? While both are specialized PDF formats, they serve entirely different purposes.
PDF/A is an ISO-standardized archival format designed for long-term preservation. It restricts certain features (such as encryption and external content) to ensure a document remains self-contained and readable decades into the future.
Linearized PDF, on the other hand, is focused entirely on delivery performance. It restructures a PDF’s internal layout to enable fast, page-by-page streaming over a network. A document can, in fact, be both PDF/A-compliant and linearized at the same time — the two optimizations are not mutually exclusive.
In short: choose PDF/A for archival integrity, linearization for fast web delivery, and apply both when your use case demands long-term storage alongside high-performance access.
When to PDF Linearize Your Documents
Linearizing pays off most when two conditions align: the document is large, and users access it remotely. If your organization matches any of the scenarios below, PDF linearization should be part of your document workflow.
- Remote and hybrid workforces: Staff working from home or in the field rarely have enterprise-grade bandwidth. Linearization absorbs network variability gracefully.
- Multi-hundred-page documents: Technical manuals, legal contracts, financial reports, or insurance policy books all benefit dramatically from on-demand page delivery.
- Mobile users with limited data plans: Transmitting only the pages a user actually reads can reduce data consumption by 80% or more on very large files.
- High-traffic document portals: Serving hundreds of concurrent users? Linearization reduces server load because transfers terminate early when users close a document.
- Healthcare and government workflows: Large patient records or regulatory filings that must be accessed quickly without storing copies locally.
How to Tell If a PDF Is Already Linearized
You can identify a linearized PDF by inspecting its raw file header. Open the file in any plain-text editor (Notepad ++, TextEdit, VS Code) and look near the top for a dictionary entry that looks like this:
<<
/Linearized 1
/L 148887844
/H [ 1139 11376 ]
/O 10792
/E 42176599
/N 2229
/T 148875428
>>
The “/Linearized 1” flag confirms the document was saved in linearized format. If it is absent, the file is a standard (non-linearized) PDF.
How to Create Linearized PDF Files
Ready to create linearized PDF documents?
Using eViewer’s Built-In Server Functions
MS Technology’s eViewer includes server-side linearization capabilities that can automatically process and re-linearize documents when they are uploaded to your system, no additional coding required. This is the simplest path for organizations already using eViewer as their document viewing platform.
Best practice: Build linearization into your document acceptance pipeline so every uploaded PDF is automatically re-linearized on arrival, ensuring consistency regardless of its origin.
How eViewer Maximizes Linearized PDF Benefits
MS Technology’s eViewer HTML5 was purpose-built to leverage linearized PDFs at every layer of the viewing experience, from the server to the end-user’s interface. Here is what sets it apart:
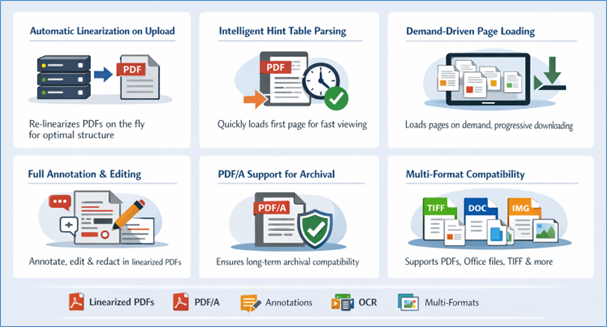
- Automatic linearization on upload: eViewer’s server component can detect and re-linearize incoming PDFs on the fly, ensuring your document library maintains optimal structure without manual intervention.
- Intelligent hint table parsing: When a linearized PDF is opened, eViewer reads the hint tables first and suspends the download after the first page group is received — letting users start reading within seconds.
- Demand-driven page loading: Pages are fetched and rendered exactly when users navigate to them, not before. But background downloads fill in the rest of the document progressively.
- Full annotation and manipulation support: Linearized documents in eViewer support the same editing, annotation, comparison, redaction, and OCR features as standard PDFs.
- PDF/A support for long-term archival: eViewer fully supports PDF/A documents, ensuring that archival-grade files can be viewed, validated, and managed within the same platform. Whether your organization needs to access historically preserved records or maintain compliance with long-term retention standards, eViewer handles PDF/A files seamlessly alongside linearized PDFs, no separate application required.
- Multi-format compatibility: eViewer displays far more than PDFs. TIFF, MODCA, Microsoft Office files, and dozens of other formats are supported alongside linearized PDFs in the same interface.
Ready to see linearized PDF performance in action? Visit the eViewer.net website for a live demo, or contact the MS Technology team at mstusa.in to set up an evaluation in your own environment.
Conclusion: Make Every Byte Count
PDF linearization is one of those decisions that is nearly invisible when it is working well, and painfully obvious when it is not. For organizations managing large, network-served documents, linearizing is not a luxury; it is a fundamental requirement for a professional user experience.
Contact MS Technology today to learn how eViewer can transform the way your organization delivers documents — faster, smarter, and at lower cost.
Share This Article